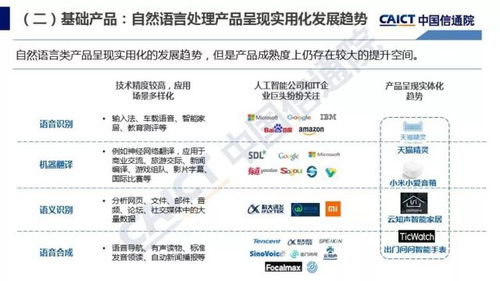
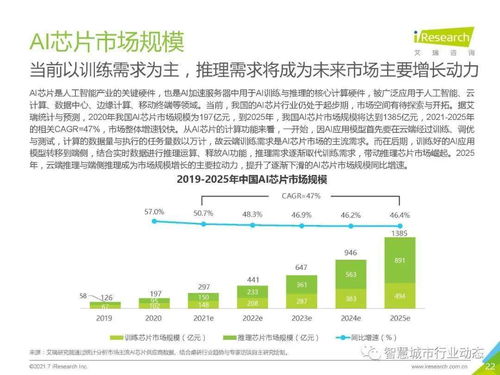
引言:智能决策的核心引擎
在人工智能的宏伟蓝图中,强化学习正成为驱动智能体在复杂、动态环境中自主决策的核心引擎。与依赖大量标注数据的监督学习不同,强化学习通过智能体与环境的持续交互来学习最优策略,这种试错与奖励驱动的范式,使其在游戏AI、机器人控制、自动驾驶、资源优化等开放性问题中展现出巨大潜力。而Python,凭借其简洁的语法、丰富的科学计算库和活跃的社区,已成为学习和实践强化学习算法的首选语言。掌握基于Python的强化学习,不仅是理解前沿AI的关键,更是开发下一代智能应用软件的基础。
一、理解强化学习的核心范式与基础构件
强化学习围绕着 智能体(Agent)、环境(Environment)、状态(State)、动作(Action) 和 奖励(Reward) 这几个核心概念展开。其核心思想是:智能体在某个状态下采取一个动作,环境随之转移到新状态并给予一个奖励信号,智能体的目标是学习一个策略(Policy),以最大化长期累积奖励。
- 核心概念与马尔可夫决策过程(MDP):MDP为强化学习提供了形式化框架,它假设未来状态仅依赖于当前状态和动作(马尔可夫性)。理解状态转移概率、策略函数、价值函数(状态价值函数V(s)和动作价值函数Q(s, a))以及贝尔曼方程,是打开强化学习大门的钥匙。
- 探索与利用的权衡:这是强化学习的根本挑战。智能体需要在尝试新动作以发现更好策略(探索)和利用当前已知的最佳动作以获得奖励(利用)之间取得平衡。ε-贪婪策略、Softmax策略等是解决这一问题的经典方法。
二、掌握主流的Python强化学习算法与实现
Python生态为快速实现和实验各类算法提供了强大支持,主要库包括 Gym/ Gymnasium(环境标准库)、Stable-Baselines3(算法实现库)、PyTorch/TensorFlow(深度学习框架)等。
- 经典表格型方法:适用于状态和动作空间离散且较小的问题。
- Q-Learning:一种离策略(off-policy)的时间差分学习算法,直接优化动作价值函数Q(s, a)。其更新公式
Q(s,a) ← Q(s,a) + α [r + γ * max_a' Q(s',a') - Q(s,a)]直观体现了基于未来最优估计的当前值更新。
- SARSA:一种在策略(on-policy)算法,其更新基于实际执行的下一动作,公式为
Q(s,a) ← Q(s,a) + α [r + γ * Q(s',a') - Q(s,a)]。
- 深度强化学习(DRL)方法:当状态空间高维(如图像)或连续时,需用深度神经网络作为函数逼近器。
- Deep Q-Network (DQN):将Q-Learning与深度神经网络结合,通过经验回放缓冲区和目标网络解决数据相关性与目标不稳定的问题,是处理高维观测的里程碑。
- 策略梯度方法:如REINFORCE,直接参数化策略并沿提高期望回报的方向调整参数。其进阶版本Actor-Critic架构融合了价值函数(Critic)和策略函数(Actor),通过Critic提供的优势估计来降低策略更新的方差,代表算法有A2C/A3C、PPO(近端策略优化)和SAC(柔性演员-评论家)。其中,PPO因其良好的性能与稳定性,已成为当前实践中最受欢迎的算法之一。
三、开发流程:从原型到稳健的智能算法软件
基于Python开发一个强化学习解决方案,是一个迭代的工程过程。
- 问题定义与环境构建:使用Gym接口定义或封装你的问题环境。确保状态、动作空间和奖励函数设计合理,奖励函数尤其关键,它引导着智能体的学习目标。
- 算法选择与原型开发:根据问题特性(离散/连续动作、观测类型等)选择基础算法。利用Stable-Baselines3等库可以快速搭建训练原型。核心代码通常包括:环境初始化、模型定义、训练循环(收集经验、更新模型)、模型保存与评估。
- 训练、调试与超参数优化:强化学习训练不稳定、对超参数敏感。需要系统性地调整学习率、折扣因子、网络结构、探索参数等。使用TensorBoard等可视化工具监控训练曲线(如回合奖励、策略熵)至关重要。
- 性能评估与部署:在独立的测试环境中评估训练好的策略,确保其泛化能力和鲁棒性。将训练好的模型集成到最终的应用程序或服务中,这可能涉及模型格式转换、创建推理API或嵌入到边缘设备。
四、应对现实世界的人工智能挑战
将强化学习从实验室环境推向现实世界,面临着独特挑战,这也是智能算法软件开发的前沿方向。
- 样本效率与安全探索:现实交互成本高昂。研究如模型基强化学习、示范学习、安全约束策略优化等方法,以提高学习效率并确保探索过程安全。
- 泛化与迁移:使在一个环境中学到的策略能够适应相似但不同的新环境。元强化学习和领域随机化是有效的技术途径。
- 多智能体协作与竞争:许多现实问题涉及多个智能体。多智能体强化学习研究智能体之间的交互,探索合作、竞争与沟通的机制。
- 可解释性与可靠性:对于关键应用,需要理解智能体为何做出特定决策,并确保其行为稳定可靠。这是将强化学习算法转化为可信赖的基础软件的重要组成部分。
##
Python强化学习算法是连接人工智能理论与强大应用软件的桥梁。从深入理解MDP和贝尔曼最优原理,到熟练运用DQN、PPO等先进算法解决实际问题,再到应对样本效率、安全部署等工程挑战,这一学习路径不仅培养开发智能算法的硬核技能,更塑造一种让机器通过交互与反思来优化决策的系统性思维。随着AI不断渗透至各行各业,掌握这项技术,意味着你正亲手参与构建能够自主适应、学习并战胜复杂挑战的下一代智能系统的基础软件层。